

I'm happy to share a good news: our paper "FAITH: A Framework for Assessing Intrinsic Tabular Hallucinations in Finance" has been accepted to the ACM International Conference on AI in Finance (ICAIF 2025) for oral presentation, which will be held in Singapore.
This work is done by CAESARS team at Asian Institute of Digital Finance, National University of Singapore, and it sits at the intersection of two things we care about a lot: trustworthy AI and reliable financial information.
Why this matters
Today, large language models (LLMs) are increasingly used to read financial reports, summarise company performance, and answer questions about earnings, risk, and growth. They can be very helpful—but they also sometimes "hallucinate": confidently giving answers that sound right but are actually wrong.
In finance, even a small mistake in a percentage or a billion vs million can matter a lot. Our work looks at this problem from a simple angle:
When an AI model is given a real company's financial tables, can it stick to the facts that are already there, instead of making numbers up?
FAITH is our attempt to systematically test this behaviour on real-world financial filings. Just as importantly, the way we build the dataset is scalable: with relatively little manual work, anyone can plug in their own reports and generate a similar hallucination-assessment dataset. For enterprises, this makes it much easier to quickly construct in-house test sets and gauge the risk of adopting AI models in their day-to-day workflows.
An open dataset for financial AI
To make this useful beyond our own group, we have open-sourced the FAITH dataset.
In plain terms, FAITH is a curated collection of:
- Real S&P 500 companies' annual reports (10‑K filings)
- The financial tables inside those reports
- Short snippets of text that refer to numbers in those tables
- The "correct" numbers that the model is supposed to recover
If you are building or evaluating AI models for finance, FAITH gives you a way to check how often a model stays true to the original tables vs. drifting into made‑up numbers.
You can find more details and links to the data and code here:
- Project page: https://zhang-mengao.github.io/FAITH/
- GitHub repo: https://github.com/zhang-mengao/FAITH
A quick look at the numbers
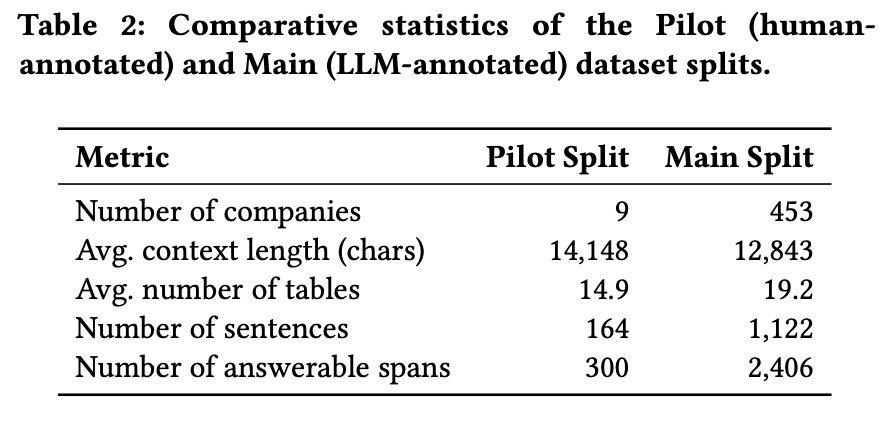
Here are a few headline stats about the FAITH dataset:
- It covers hundreds of S&P 500 companies from their latest 10‑K filings.
- It includes over two thousand short text snippets where the discussion in the report refers to specific numbers in the tables.
- All in, there are a few thousand individual data points (number‑and‑unit pairs) that can be used to test whether an AI model reads and uses the tables correctly.
In other words, FAITH is large enough to stress‑test modern AI models, but focused enough to stay close to real, everyday financial analysis tasks.
Want to dive deeper?
This post is just a high-level overview. For a more detailed walkthrough of FAITH—the research questions behind it, how we build the dataset step by step, and what we learn from benchmarking different models—please see this in‑depth blog post.
Thanks to everyone who contributed to this project. If you're interested in trustworthy AI in finance, feel free to explore the dataset, run your own experiments, or reach out—we'd love to hear what you discover.