On 18 November 2025, our paper "FAITH: A Framework for Assessing Intrinsic Tabular Hallucinations in Finance" will be presented at the 6th ACM International Conference on AI in Finance (ICAIF '25) in Singapore. FAITH is our attempt to answer a simple but uncomfortable question:
When an AI reads your financial statements, how often is it quietly wrong?
In this blog, we share the motivation behind FAITH, how the framework works, and what we learned when we put today's leading large language models (LLMs) under stress.
Why hallucinations are especially dangerous in finance
LLMs are already being used to read annual reports, draft research notes, answer client questions, and help analysts navigate complex disclosures. They are remarkably good at turning long documents into concise explanations.
But finance is unforgiving:
- A misplaced decimal or wrong unit (million vs billion) can completely change the story.
- Many important numbers are not written in plain text – they sit inside dense tables.
- Decisions must be traceable: "where did this number come from?" is not a rhetorical question for regulators and risk managers.
When an LLM produces an answer that sounds plausible but does not actually match the underlying table or text, we call this an intrinsic hallucination – the model contradicts the context it was given. FAITH focuses precisely on this type of failure.
What FAITH actually measures
Most existing hallucination benchmarks test models on open‑domain facts (often built from Wikipedia) or simple question‑answering over short passages. Financial work is different: we care about numbers grounded in real filings, often involving multi‑step calculations over tables.
FAITH is built around three principles:
-
Real documents, not toy examples We build the benchmark directly from 2024 10‑K annual reports of S&P 500 companies. These filings are long, table‑heavy, and subject to regulatory scrutiny – exactly the kind of documents financial institutions use every day.
-
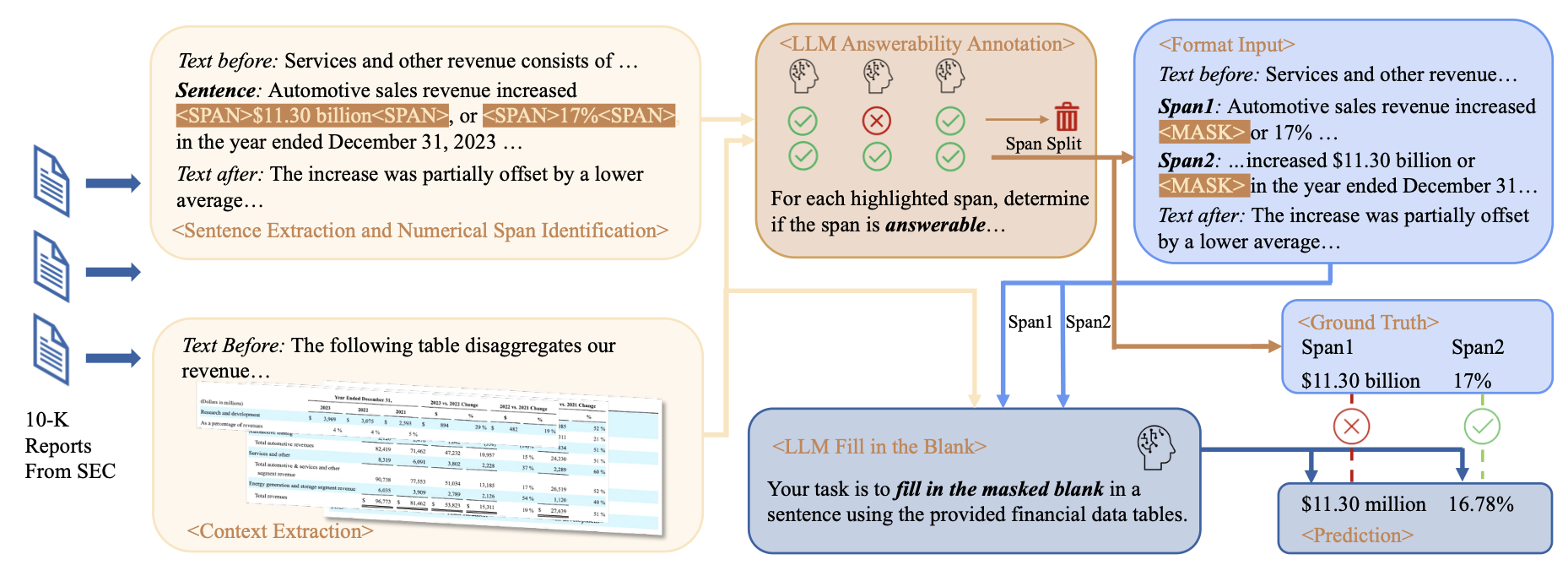
Masked‑span prediction instead of Q&A Rather than asking open questions, FAITH turns the problem into a fill‑in‑the‑blank task:
- We find sentences in the "Management's Discussion and Analysis" section that mention financial quantities (e.g. "Revenue increased by $11.30 billion or 17% in 2023…").
- We then mask one of the numeric spans: "Revenue increased by [MASK] or 17% in 2023…"
- The model receives:
- the corrupted sentence,
- nearby text,
- and the relevant financial tables.
- Its job is to recover the missing value based only on this context.
If the model fills in the blank with the wrong value or wrong unit, that counts as a hallucination with respect to the document.
-
Automatic, scalable dataset creation Manually labelling thousands of such examples would be painfully slow. Instead, FAITH uses a carefully designed pipeline:
- Detect numeric spans and their associated units (%, $, million, per share, etc.).
- Filter out spans that are ambiguous, inconsistent, or impossible to recover from the tables.
- Use a committee of strong LLMs to help decide whether a span is answerable from the given context, and keep only those with strong agreement.
- Normalize numbers to a shared scale (e.g. "1.23 billion" vs "1,230 million") so equivalent answers are not unfairly penalized.
The result is a large‑scale, realistic benchmark that can be recreated on proprietary documents inside an institution's own perimeter.
Four types of financial reasoning we test
Not all numeric questions are created equal. To understand where models struggle, we categorize each masked span into one of four reasoning scenarios:
-
Direct Lookup (A) The answer is simply copying a value from a single cell in a table. Example: "Total revenue in 2024 was [MASK]."
-
Comparative Calculation (B) The answer requires a simple comparison over time or category. Example: "Revenue increased by [MASK]% year‑over‑year," when revenues for 2023 and 2024 are both present in the table.
-
Bivariate Calculation (C) The answer is computed from two different metrics. Example: "Gross margin was [MASK]%," combining revenue and cost of goods sold.
-
Multivariate Calculation (D) The most demanding case: multi‑step formulas involving several variables and latent quantities. Example: computing the equity portion of an investment when only the total purchase price, leverage, and ownership share are given across text and tables.

By tracking accuracy across these scenarios, FAITH can tell you not only how often a model hallucinates, but how quickly things break down as the reasoning chain becomes more complex.
What we found when we tested today's LLMs
We evaluated a mix of proprietary and open‑source models, from lightweight 8B‑parameter models to frontier‑scale systems.
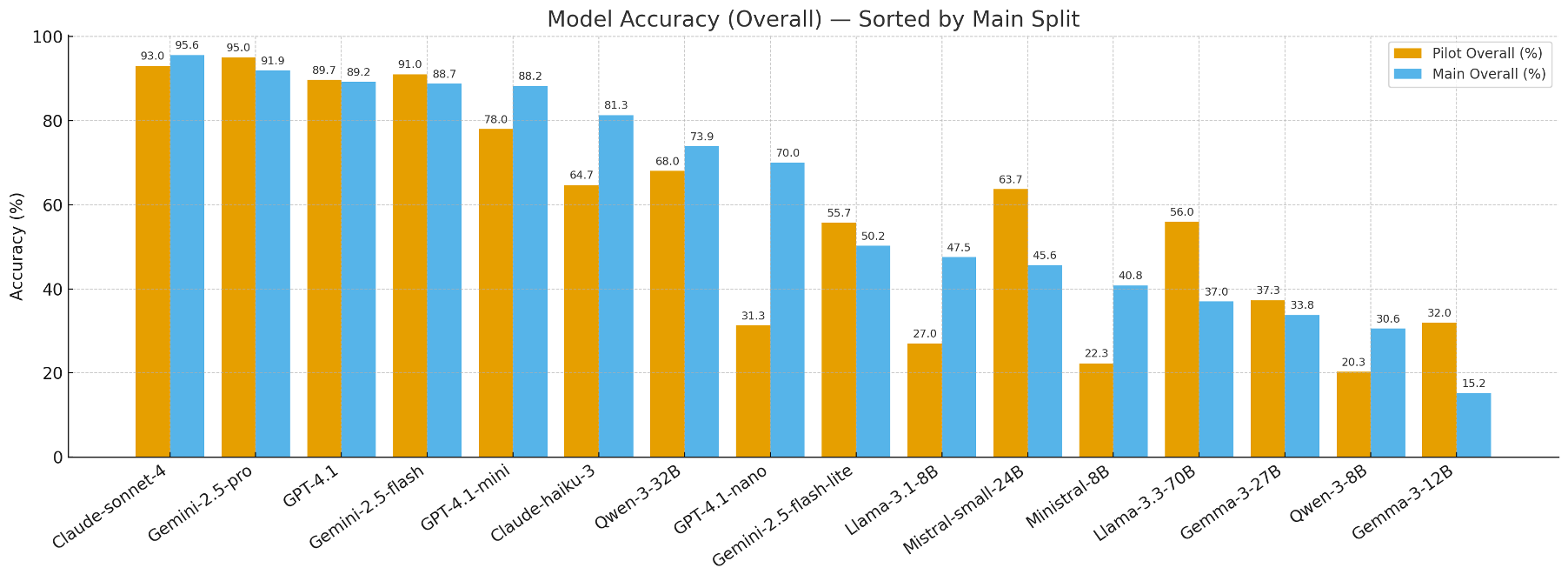
1. A clear hierarchy of reliability
- Top‑tier proprietary models (e.g. Claude‑Sonnet‑4, Gemini‑2.5‑Pro) reach around 92–96% accuracy on our main benchmark split.
- Strong general models like GPT‑4.1 and GPT‑4.1‑mini follow closely behind.
- Many smaller or mid‑sized open‑source models fall far short, often below 50% accuracy overall and near zero on the hardest reasoning cases.
In other words: even among very capable models, there is a measurable and meaningful gap in how faithfully they handle financial tables.
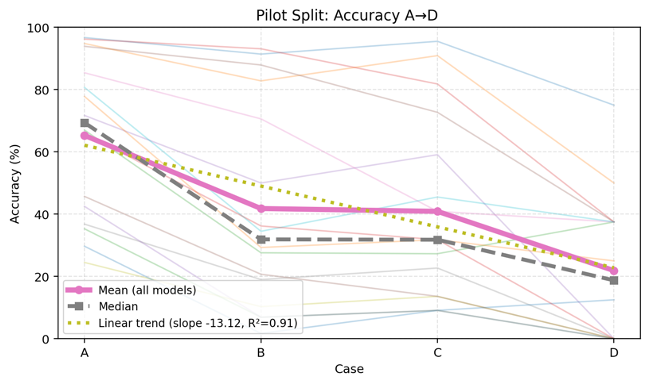
2. Complexity is the main failure driver
For almost every model, performance follows the same pattern:
Direct lookups are relatively easy; multi‑step quantitative reasoning is where hallucinations explode.
Models do quite well when they only need to copy a number from a table. But as soon as we ask them to combine multiple figures, translate between percentages and absolute values, or reason across both text and tables, error rates rise sharply.
On the Multivariate Calculation scenario, many models completely collapse, mis‑computing key quantities or ignoring parts of the context altogether.
3. Scale errors are surprisingly common
One of the most striking error types we observed is the scale mismatch:
- The model identifies the right number, but attaches the wrong magnitude – for example, answering "150 million".
- These mistakes are easy to miss in a quick skim, yet devastating in practice.
When we hypothetically "fixed" only scale errors in some models, their accuracy jumped by 15–20 percentage points. This suggests that explicit handling of units and scales remains a major open problem in LLM design and prompting.
4. A case study: who really understands the capital structure?
For one challenging example, the model had to infer the equity investment in a shopping centre from:
- an ownership percentage,
- a pro‑rata share of mortgage debt in a table, and
- the total purchase price described in the text.
Only one frontier model successfully reconstructed the full chain:
- Backed out the total debt from the pro‑rata amount and ownership share.
- Subtracted this from the purchase price to get total equity.
- Applied the fund's ownership percentage to arrive at the correct equity investment.
Most other models simply multiplied the purchase price by the ownership share, ignoring leverage entirely – a plausible‑sounding but financially wrong answer. This illustrates how intrinsic hallucinations can stem from shallow "pattern matching" rather than true financial reasoning.
Why FAITH matters for financial institutions
For banks, asset managers, insurers and regulators, FAITH offers two things:
-
A realistic benchmark Because the dataset is built from real S&P 500 10‑Ks, performance on FAITH is much more indicative of how a model will behave when exposed to actual reporting pipelines, not just curated academic examples.
-
A reusable methodology The same pipeline we used to build FAITH can be applied to your own documents:
- ingest internal credit memos, risk reports, or client decks,
- generate masked‑span tasks automatically,
- and measure how faithfully candidate models recover numbers and units.
This makes FAITH not just a static dataset, but a general recipe for in‑house hallucination testing under your own definitions of "what matters".
Try FAITH yourself
We have open‑sourced:
- the benchmark dataset,
- the data construction pipeline, and
- example evaluation scripts for popular LLMs.
If you work with financial AI and care about model risk, we invite you to:
- run FAITH on your own models,
- adapt the pipeline to your proprietary documents,
- and share feedback or extensions with us.
You can find more details and links to the data and code here:
- Project page: https://zhang-mengao.github.io/FAITH/
- GitHub repo: https://github.com/zhang-mengao/FAITH
Together, we hope FAITH can help move the conversation about "AI in finance" from demo‑level excitement to measured, evidence‑based trust.